Codage de Huffman
Le codage de Huffman
David Huffman a proposé en 1952 une méthode statistique qui permet d'attribuer un mot de code binaire aux différents symboles à compresser (pixels ou caractères par exemple). La longueur de chaque mot de code n'est pas identique pour tous les symboles: les symboles les plus fréquents (qui apparaissent le plus souvent) sont codés avec de petits mots de code, tandis que les symboles les plus rares reçoivent de plus longs codes binaires. On parle de codage à longueur variable (en anglais VLC pour variable code length) préfixé pour désigner ce type de codage car aucun code n'est le préfixe d'un autre. Ainsi, la suite finale de mots codés à longueurs variables sera en moyenne plus petite qu'avec un codage de taille constante.
Le codeur de Huffman crée un arbre ordonné à partir de tous les symboles et de leur fréquence d'apparition. Les branches sont construites récursivement en partant des symboles les moins fréquents.
La construction de l'arbre se fait en ordonnant dans un premier temps les symboles par fréquence d'apparition.
successivement les deux symboles de plus faible fréquence d'apparition sont retirés de la liste
et rattachés à un noeud dont le poids vaut la somme des fréquences des deux symboles. Le symbole
de plus faible poids est affecté à la branche 1, l'autre à la branche 0 et ainsi de suite en considérant
chaque noeud formé comme un nouveau symbole, jusqu'à obtenir un seul noeud parent appelé racine.
Le code de chaque chaque symbole correspond à la suite des codes le long du chemin allant de ce caractère
à la racine. Ainsi, plus le symbole est "profond" dans l'arbre, plus le mot de code sera long.
Soit la phrase suivante : "COMMENT_CA_MARCHE". Voici les fréquences d'apparitions des lettres
| M | A | C | E | _ | H | O | N | T | R |
| 3 | 2 | 2 | 2 | 2 | 1 | 1 | 1 | 1 | 1 |
Voici l'arbre correspondant :
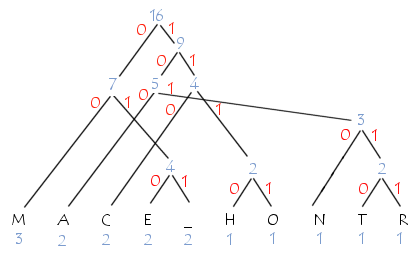
Les codes correspondants à chaque caractère sont tels que les codes des caractères les plus fréquents sont courts et ceux correspondant aux symboles les moins fréquents sont longs :
| M | A | C | E | _ | H | O | N | T | R |
| 00 | 100 | 110 | 010 | 011 | 1110 | 1111 | 1010 | 10110 | 10111 |
Les compressions basées sur ce type de codage donnent de bons
taux de compressions, en particulier pour les images monochromes (les fax par exemple).
Il est notamment utilisé dans les recommandations T4 et T5 de l'ITU-T